「stringr」パッケージが使いやすいと評判だったので、今更ながら書いてみました。
実施環境については、以下の通りです。
・MacBook Air(CPU:1.6GHz,Memory 8GB)
・macOS Sierra ver10.12.3
・RStudio ver 1.0.136
・macOS Sierra ver10.12.3
・RStudio ver 1.0.136
思ってたよりも簡単だったソースコードのご紹介
実施前は難しいかなと思っていましたが、やってみたら意外と簡単でした。
# パッケージの読み込み。
# 「xlsx」形式の読み込みは他にもパッケージがありますが、Javaの導入など面倒が増えるので、このパッケージがオススメです。ただし、「xls」形式は読めません。
library(openxlsx)
library(dplyr)
# データの読み込み
setwd("~/blog/hotel_170819_TM")
hotel.dat <- read.xlsx("170819_hotel.xlsx")
# カラム名を表示します。不要なカラムもたくさん含まれています。
colnames(hotel.dat)
[1] "url" "rank" "com_title"
[4] "com_title_link" "user" "time1"
[7] "com_sentence" "flg1" "flg1_link"
[10] "flg2" "flg2_link" "flg3"
[13] "flg3_link" "purpose1" "purpose2"
[16] "purpose3" "time2" "reply_sentence"
[19] "plan1" "plan2_link" "plan2"
# 分析データをattachします。「hotel.dat$hoge」と入力せずに、hogeで狙ったカラムにアクセスできます。
attach(hotel.dat)
# 分析に必要なカラムだけ抜き出します。見た目はわかりづらいですが、「dplyr」パッケージのおかげです。
hotel2.dat <- select(hotel.dat,rank,user,time1,com_sentence,purpose1,purpose2,purpose3,time2,reply_sentence,plan1,plan2)
# データ内容を確認してみます。
View(hotel2.dat)
# 「xlsx」形式の読み込みは他にもパッケージがありますが、Javaの導入など面倒が増えるので、このパッケージがオススメです。ただし、「xls」形式は読めません。
library(openxlsx)
library(dplyr)
# データの読み込み
setwd("~/blog/hotel_170819_TM")
hotel.dat <- read.xlsx("170819_hotel.xlsx")
# カラム名を表示します。不要なカラムもたくさん含まれています。
colnames(hotel.dat)
[1] "url" "rank" "com_title"
[4] "com_title_link" "user" "time1"
[7] "com_sentence" "flg1" "flg1_link"
[10] "flg2" "flg2_link" "flg3"
[13] "flg3_link" "purpose1" "purpose2"
[16] "purpose3" "time2" "reply_sentence"
[19] "plan1" "plan2_link" "plan2"
# 分析データをattachします。「hotel.dat$hoge」と入力せずに、hogeで狙ったカラムにアクセスできます。
attach(hotel.dat)
# 分析に必要なカラムだけ抜き出します。見た目はわかりづらいですが、「dplyr」パッケージのおかげです。
hotel2.dat <- select(hotel.dat,rank,user,time1,com_sentence,purpose1,purpose2,purpose3,time2,reply_sentence,plan1,plan2)
# データ内容を確認してみます。
View(hotel2.dat)
今回用いたデータセットでは、user列に、「ユーザー名・年代・性別」データが同一カラムに入っていました。年代・性別は分析に有用なので別カラムに切り出したいです。
| 小田一弥さん [30代/男性] |
| user_name | age | sex |
| 小田一弥さん | 30代 | 男性 |
「おっと、正規表現だな・・・」と思われたあなた、大丈夫です。
自分も不慣れですが、今回はとっても簡単です。
# パッケージを読み込みます。最初は「for」で繰り返し処理を書こうと思ったのですが、こちらの方がずっとシンプルで早いそうです。
library(stringr)
# userの名前と年代・性別を分離
hotel2.dat$user_name <- str_extract(hotel2.dat$user,"^.*さん")
hotel2.dat$age <- str_extract(hotel2.dat$user,"\\d{2}代")
hotel2.dat$sex <- str_extract(hotel2.dat$user,".性")
library(stringr)
# userの名前と年代・性別を分離
hotel2.dat$user_name <- str_extract(hotel2.dat$user,"^.*さん")
hotel2.dat$age <- str_extract(hotel2.dat$user,"\\d{2}代")
hotel2.dat$sex <- str_extract(hotel2.dat$user,".性")
View関数で見ると下記のようになります。

# パッケージを読み込みます。
library(rpivotTable)
# グラフ化します
rpivotTable(hotel2.dat)
library(rpivotTable)
# グラフ化します
rpivotTable(hotel2.dat)
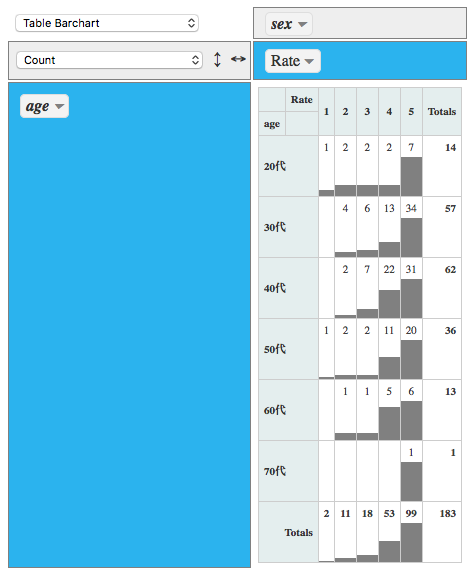
以上です。
R関連エントリー
R言語:starwarsキャラの身長や年齢をdplyrで加工してggplot2する。http://sapporomkt.blogspot.jp/2017/08/rstarwarsdplyrggplot2.html
RESASの不動産取引データでheatmapを作ってみた。
http://sapporomkt.blogspot.jp/2017/05/resasheatmap.html
RESASデータを「IBM Data Scientist Workbench」でゴニョゴニョしてみた。
http://sapporomkt.blogspot.jp/2017/05/resasibm-data-scientist-workbench.html
ggplot2でクロス集計的に複数グラフをプロットする方法
http://sapporomkt.blogspot.jp/2016/11/ggplot2.html
R開発環境が無料で簡単導入!「Data Scientist Workbench」を使ってみた。
http://sapporomkt.blogspot.jp/2016/10/rdata-scientist-workbench.html
(Bluemix)知ってた?dashDBってTwitter分析にもツカエルのさ(+ちょっとだけコンサドーレ調べ)
http://sapporomkt.blogspot.jp/2016/07/bluemixdashdbtwitter.html
RMeCabで形容詞の形態素解析をやってみた。
http://sapporomkt.blogspot.jp/2016/07/rmecab.html
【R言語】今年は、leafletでマップをグリグリしたい。
http://sapporomkt.blogspot.jp/2016/01/rleaflet.html
(R言語)当ブログアクセス者の興味関心事をコレポン(コレスポンデンス)した。
http://sapporomkt.blogspot.jp/2015/12/r.htm
0 件のコメント:
コメントを投稿