Bluemixが使える状態になっていれば、統計やデータサイエンス等の特別な知識不要で、どなたでも出来ると思います。
最後にローカル環境のRで数行のコードを走らせていますが、下記のようなアウトプットが簡単に作成できます。

※本エントリーは、私、小田一弥が一個人として勉強を兼ねて記載したものです。私の勤務先である日本アイ・ビー・エム株式会社の見解・見識ではない、個人としての記載内容としてご覧ください。
手順のご紹介
Bluemixの登録方法と「dashDB」「Insights for Twitter」両サービスの設置等については、既に様々なエントリーで紹介されているので割愛します。
特に両サービスともBluemix上での設置はガイドに沿ってボタンを押すだけなので、初見でも迷うところは皆無でした。
ちなみに、今回使用しているBluemixの各サービスは無料プラン内で充分遊べますので、出費など気にせず遊んでみてください。
1.「dashDB」と「Insights for Twitter」を設置済みの状態からスタート
Bluemix上で「dashDB」と「Insights for Twitter」を設置した状態から説明をスタートします。
他のエントリー等を参照しながらトライしてみてください。Qiita等にあるエントリーがわかりやすいと思います。

2.「dashDB」をオープン
「dashDB」右上の「OPEN」ボタンを押してください。

画面左側メニューから「Load>Load Twitter Data>」を選択してください。

「Use an exising Twitter service:」のプルダウンメニューで事前に設置した「Insights for Twitter」のサービスを選択してください。

3.検索したいTweetを指定
今回は、当ブログでも何度か分析対象として取り上げている「コンサドーレ」について調べてみます。
ハッシュタグで「#consadole」 と書かれたTweetは「38,271件」検索可能なことがわかります。

4.テーブルで識別するための名称を記載
「Load the data into new tables with this prefix:」欄で、「consadole」と入力すると、 各カラム名称が動的に変更されます。

5.Tweetデータのロード開始
前の画面の「Next」ボタンを押すと、下記画面のように「dashDB」上にTweetデータをロードし始めます。今回は件数が多いので結構時間がかかりますが、数千件なら数分で取得できると思います。

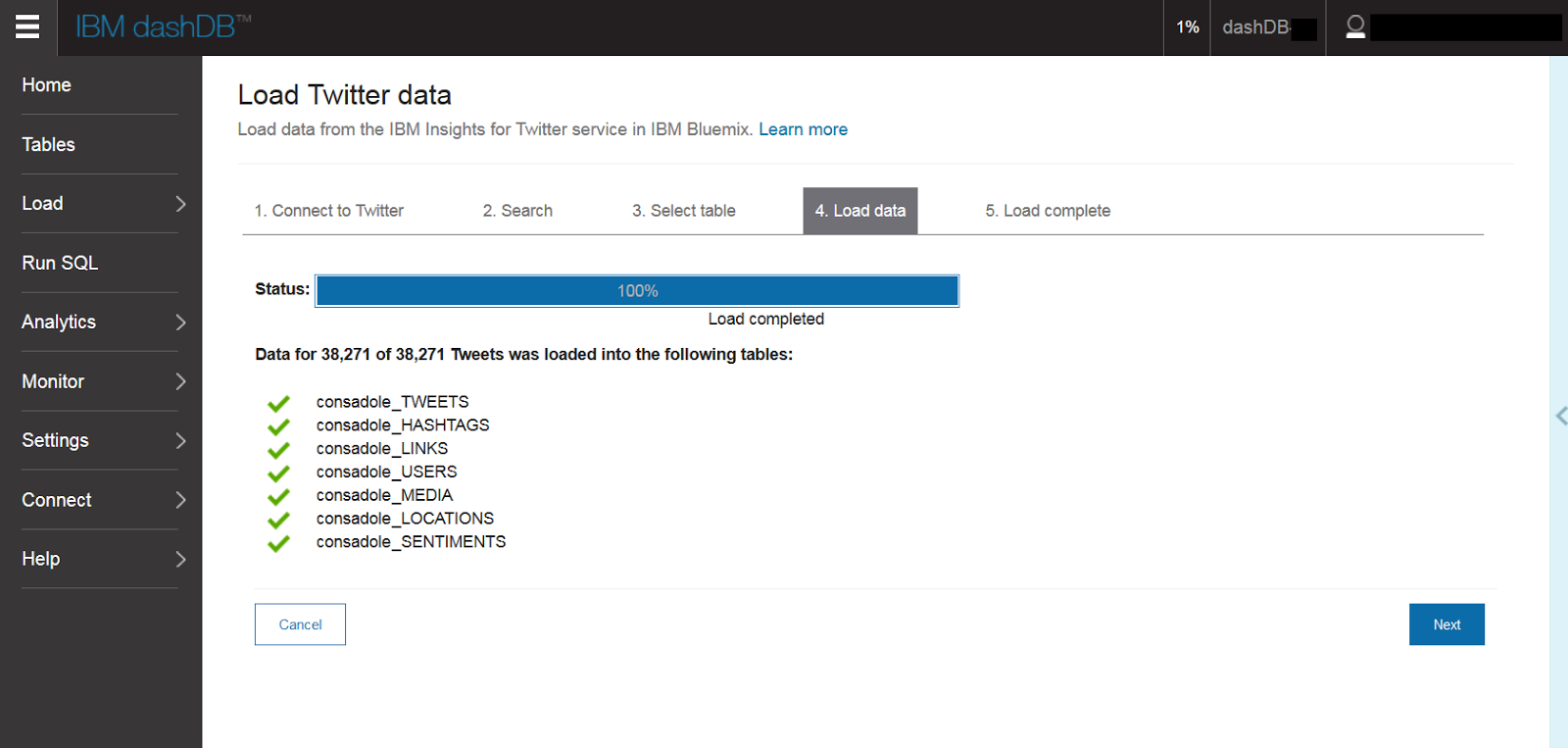
6.「Statistics」の表示
Loadが完了すると、下記のような統計情報が一覧表示されます。

下記は「#consadole」を含むTweet件数の時系列グラフ。 10分の1サンプリングがかかっているので全件数ではないですが、それでも今年はJ2で一位(2016年7月31日現在)となっている同チームが話題化していることがわかりますね。

また、その他のハッシュタグを含むグラフも出力されます。

その他、下記のようなデータも出力されます。



7.「Data」の表示
「Statistics」の横にある「Data」をクリックすると、ローデータの操作も可能となります。

テーブルメニューバーにある「↑(ダウンロード)」ボタンを押すと、ローデータがダウンロードできます。


8.日本地図上にTweetをプロット
GPS(位置情報システム)をオンにしたままTweetすると、その時に発話された経度・緯度が付加されます。今回はTweet総数がそれほど多くなかったので、190件ほどしか位置情報を取得できませんでしたが、とりあえずR言語でプロットしてみました。
ちなみにRのソースコードはこちら。
「leaflet」というRの描画用パッケージなのですが、たったこれだけでプロットできちゃいます。
radiusオプション、colorオプション、weightオプションはお好みで変えてください。
library(leaflet)
consadole_lat_lon.dat <- read.csv("consadole_lat_lon.csv",head=TRUE)
View(consadole_lat_lon.dat)
leaflet(consadole_lat_lon.dat) %>% addTiles() %>% addCircles(lng=~lon,lat=~lat,radius=100,color="#09f",weight=5)

その他、Tweetのテキストも取得可能です。Freeプランでも500万Tweetまでは無料で取得できますので、御興味ある方は是非試してみてください。
(おまけ)
「#ポケモンGO」でつぶやいた方々のマップはこちら。

R言語関連のエントリー
RMeCabで形容詞の形態素解析をやってみた。
http://sapporomkt.blogspot.jp/2016/07/rmecab.html
【R言語】leafletで札幌市内のサツドラをプロットしてみた。
http://sapporomkt.blogspot.jp/2016/01/rleaflet_4.html
【R言語】今年は、leafletでマップをグリグリしたい。
http://sapporomkt.blogspot.jp/2016/01/rleaflet.html
【R言語】factor型で数値を集計するときの注意点
http://sapporomkt.blogspot.jp/2016/01/rfactor.html
【R言語】ベクトルにおける関数の使い方
http://sapporomkt.blogspot.jp/2015/12/r_80.html
【R言語】「rpivotTable」パッケージが高機能過ぎて泣ける件
http://sapporomkt.blogspot.jp/2015/11/rrpivottable.html
【R言語】どうしても「ディープインパクト」全産駒の内訳を集計したくなったの<前処理編>。
http://sapporomkt.blogspot.jp/2015/10/r.html
AEIが優秀な種牡馬を調べてみたら・・・やっぱりディープ(略)
http://sapporomkt.blogspot.jp/2015/10/aei.html
過去5年間のリーディングサイアー成績を眺めてみた~ディープインパクトって実際・・・
http://sapporomkt.blogspot.jp/2015/10/5.html
(R言語)readHTMLTable関数でJ2の順位を音速で抜き出す。
http://sapporomkt.blogspot.jp/2015/07/rreadhtmltablej2.ht



































{kind=link}