今回は、UCIにある機械学習用として無料で公開されている「馬の疝痛(せんつう)データ」を使ってSPSS Modeler上で「決定木」をサクっと作ってみます。当エントリーの手順どおりやって頂けると、どなたでも下記のような決定木を楽勝でアウトプットできると思います。

※本エントリーは、私、小田一弥が一個人として勉強を兼ねて記載したものです。私の勤務先である日本アイ・ビー・エム株式会社の見解・見識ではない、個人としての記載内容としてご覧ください。
用語の説明等
疝痛(せんつう)とは?
疝痛(せんつう、colic)とは腹部臓器の疼痛およびそれに伴う腹痛を示す症状名。馬ではその解剖学的、生理学的特徴から多発する。以下では主に馬について記述する。馬で多発する原因として、胃が体躯に比べ小さいために嘔吐しにくい構造であること、腸間膜(mesentery)が長く固定されていないこと、巨大な盲腸をもつことなどが挙げられる。
(Wikipediaより)
ちなみに、1997年に皐月賞と日本ダービーを制した名馬「サニーブライアン」なども疝痛で命を落としていまして、お馬さん業界の中では結構メジャーで怖い病らしいです。
決定木分析とは?
対象データを統計的な基準をもとに分岐し、ツリー構造状の分類モデルを作成することにより、発生事象を予測する分析手法(教師あり学習法モデルの代表格)。葉が分類を表し、枝がその分類に至るまでの特徴の集まりを表すような木構造を示す。
手順
1.UCIのサイトからデータをダウンロード
下記サイトからローデータをダウンロードしてください。上段にある「Download: Data Folder」をクリックするとローデータが表示されます。また、当ページの下部には各データ列の詳細についての解説もあるので、後ほどデータ形式の指定時に参照します。
ちなみに、欠損値も30%ほど入っているので、置換ノードによるデータ加工のお勉強としても活用そうですね。

2.CSV形式で保存
早速データを保存しようと思ったのですが・・・。うーん、CSV形式等でもあると楽なんですけどね^^;

このまま取り込んでも何とかなるのですが、面倒なのでTerapadで半角スペースを「,(カンマ)」に全置換してCSV形式で保存しました。
(参考) Terapad公式ページ
ちなみに、Terapad、ほんとに便利ですよ。正規表現による改行やタブの置換も出来るので、調査票作成時等にも大助かりです。

3.SPSS Modelerでデータ取り込み
「入力パレット」から「可変長ファイル」ノードを設置するか、CSVファイルをそのままストリーム上にドラッグ&ドロップしてください。なお、「行区切り文字は改行文字です」にチェックをつけるのをお忘れなく。

4.「テーブル」ノードでデータ内容をチェック
取り込んだCSVファイルに「出力パレット」にある「テーブル」ノードをつなげてデータ内容をチェックしてください。「?」と表記されている部分がユーザー欠損値となります。
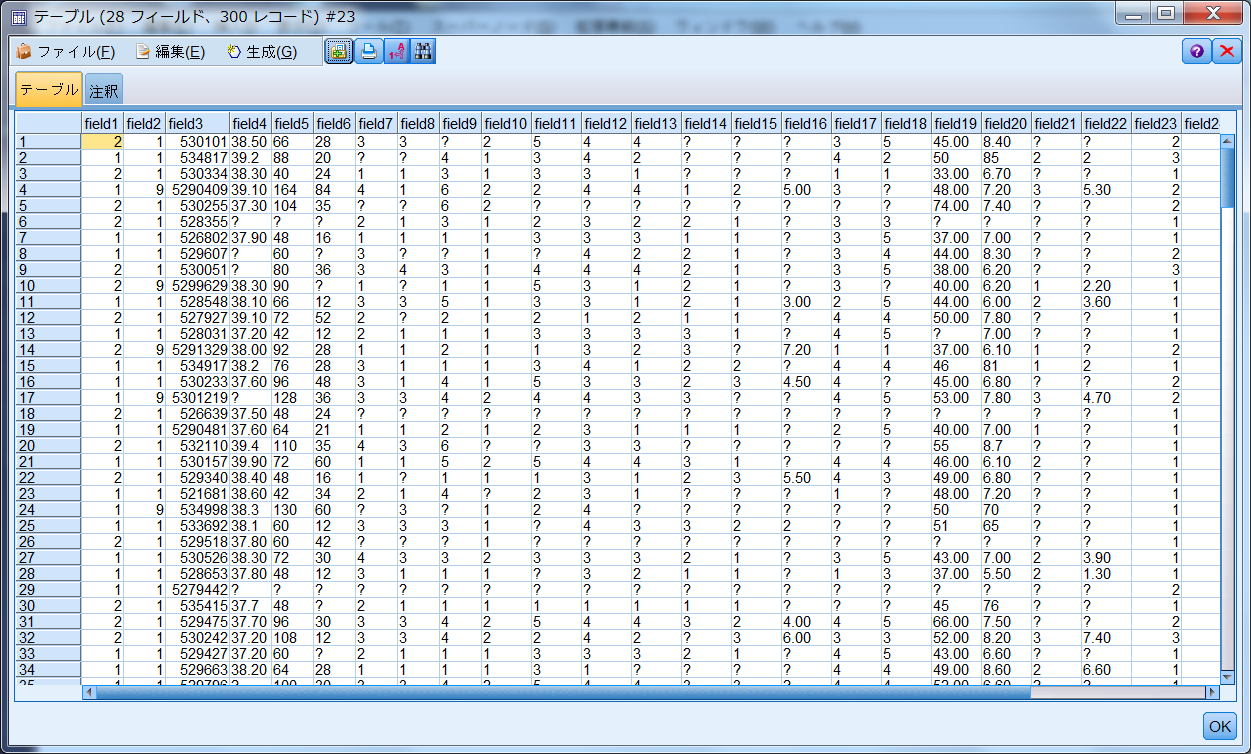
5.「データ型」ノードでホニャララ・・・できないorz
「フィールド設定」パレットから「データ型」ノードを入力ファイルにつなげてホニャララしようと思ったら・・・あら、数値データが入っているフィールドなのに、「ストレージ:文字列」になっています。

6.「フィールド作成」ノードで「整数型」に一括変換
「フィールド設定」パレットから「フィールド作成」ノードを配置してください。
・フィールドリスト:
「整数型」に変換したいフィールドを下記スクリーンショット画面のように複数選択してください。
・CLEM式:
入力欄に「to_integer(@FIELD)」と記入してください(式ビルダーでもOKです)
@FIELD関数~CLEM式が複数のフィールドに適用される場合、@FIELDは順番に各フィールドを表します。
to_integer(ITEM)関数~ITEMを整数に変換します。ITEMは文字列または数字でなければなりません。
→「フィールドリストで指定した文字列フィールドをまとめて整数型に変換してね」の意味です。

ちなみに、「データ型」ノードを通過した後に「テーブル」ノード等でデータ内容をチェックすると、いつの間にか「?(ユーザー欠損値)」が「$null$」のシステム欠損値に変換されていますね。
7.「データ型」ノードで各フィールドのストレージを確認
ハイライトしたフィールド名横のアイコンをご覧ください。先ほどのCLEM式で指示した型変換が反映されていますね。ここで変換後の各フィールドにおける尺度を変更してください。
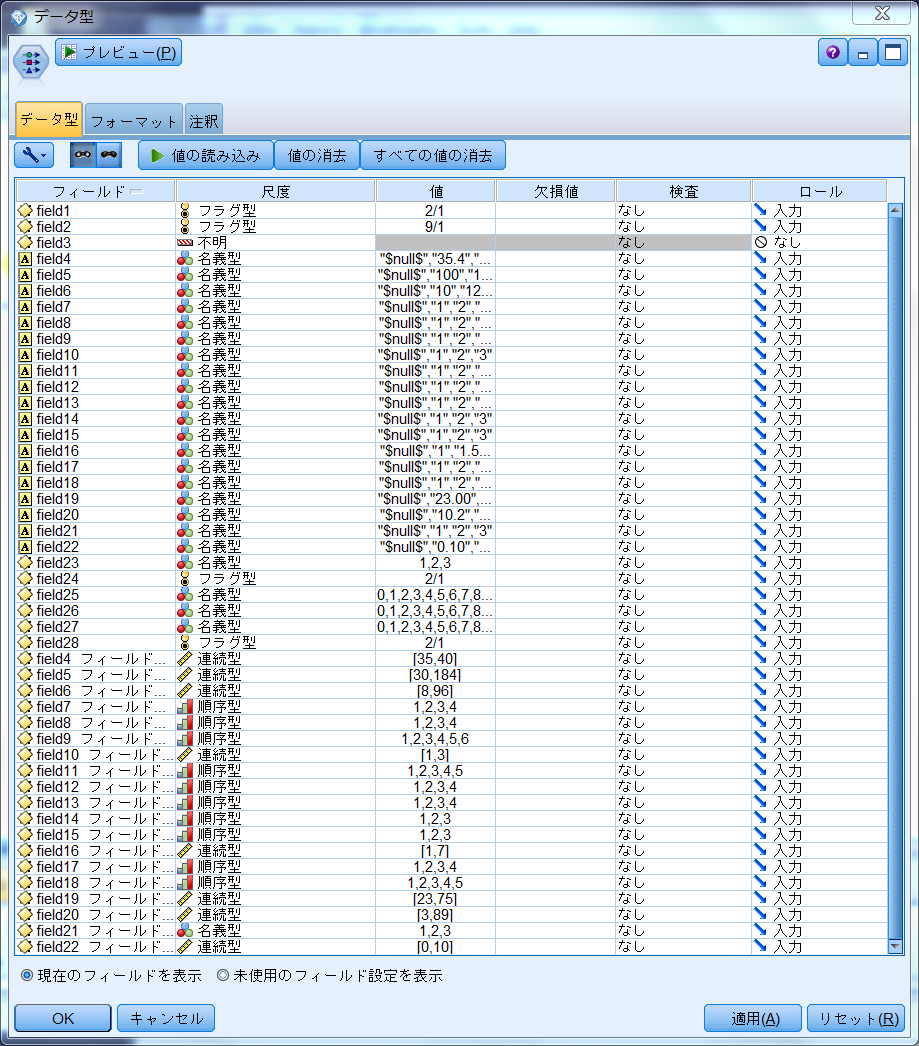
8.「フィルター」ノードで変換前のフィールドを削除
「フィールド設定」パレットにある「フィルター」ノードを配置して、「フィールド作成」で変換する前の文字列フィールドを削除してください。

9.「フィールド順序」ノードで順番を揃える
「フィールド設定」パレットにある「フィールド順序」を配置してフィールドの順番を揃えてください。

10.「フィルター」ノードでフィールド名を変更
一回目の「フィルター」ノード設置時に行ってもいいのですが、そろそろフィールド名が読み込み直後のままだと味気ないので、UCIの「Attribute Information:」を参考にしながらフィールド名を変更しします(Field25~27も不要なのでカットしました)

11.「データ型」ノードで各フィールドの値とラベルを変更
最初の「データ型」ノードで実施してもいいのですが、自分はここで行いました。
変更したいフィールドで右クリック→編集で下記画面となりますので、適宜、変更してください。

12.「CHAID」ノードを設置
さて、いよいよ決定木を作ります!
「モデル作成」ノードから「CHAID」ノードを設置してください。

予測対象としたいフィールドを選択します。今回は、「馬の疝痛治療の結果、生死がどうなったか」を表す「outcome」を選びました。予測変数には残りの変数をガサっと入れてみました。
(28:cp_dataは、「そんなに参考ならないデータ」と書かれていたので除外しました)

「作成オプション」タブは下記のように設定してください。あまり低い%を設定すると枝が分かれすぎて解釈が難しいので、これぐらいの数値がちょうど良いとのことです。


13.モデルで確認!
先ほどのノードで「実行」を押すと、ストリーム上にナゲットが生成されますので、ダブルクリックで中身をご確認ください。
生死を分かつのが「痛がってるかどうか」なのはよく分かるのですが、次の分岐が「タンパク質(多分、血中濃度)」 なのは「へぇ~」な感じでした。
実際、馬が疝痛になると脱水症状につながりやすく、結果として 「ヘマトクリット(赤血球容積比)」も高くなるそうです。ノード11・12がその部分にあたるのですが、ノード12では、当値が高くなると死亡率が高まるのが見てとれます。


なお、手順12のように「出力」パレットにある「精度分析」ノードを配置した上で、「テーブル」ノードを使ってデータを表示すると予測結果の確認も出来るので、ご興味ありましたらご覧ください。
その他:SPSS Moder関連エントリー
SPSS Modelerでアソシエーション分析がしたいっ! (前処理編〜縦持ちを横持ちへ)
http://sapporomkt.blogspot.jp/2017/06/spss-modeler.html
「SPSS Modeler Text Analytics」によるテキストマイニング(データ読み込みからグラフ化)http://sapporomkt.blogspot.jp/2016/07/spss-modeler-text-analytics.html
「SPSS Modeler」におけるデータ操作及びシーケンスデータの取り扱いまとめ
http://sapporomkt.blogspot.jp/1970/01/spss-modeler_1.html
SPSS Modelerでリーディングサイアーデータ分析:前処理(レコード追加等)
http://sapporomkt.blogspot.jp/2016/05/spss-modeler.html
SPSS Modelerで「サイアー/ブルードメアサイアー」データをレコード結合
http://sapporomkt.blogspot.jp/2016/05/spss-modeler_13.html
こんにちは。面白いデモですね。ところで最初に空白文字を',"に置換した後、'?'を除去してしまえば連続型のストレージ:整数で読み込まれだいぶ手間が省けると思うのですがいかがでしょうか。
返信削除コメントありがとうございます!確かにそうですね。仕事終わったらやってみます。
返信削除この辺り、いつも試行錯誤しながら苦労してます^^;
リプライありがとうございます。現行の手順はフィールド作成ノードやCLEM式のデモになっていて、これはこれで良いと思います。ただエディタ上で','で区切った後'?'を消してしまえばデータ型ノードを介してCHAIDノードに繋ぐだけでもうチョー簡単に出来てしまうので、これから訪問する方にはわかりやすいかな、と思いまして。
返信削除