
※本エントリーは、私、小田一弥が一個人として勉強を兼ねて記載したものです。私の勤務先である日本アイ・ビー・エム株式会社の見解・見識ではない、個人としての記載内容としてご覧ください。
サンプルデータ加工の手順
今回は、「クルマの受容性」に関するオープンデータを使ってみました。
そこそこのレコード数がありながらも、欠損値がないので、取り扱いが楽なデータです。

<サンプルデータの入手・加工方法>
1.UCIのサイトからデータをダウンロード
黄色でハイライトされている「Data Folder」をクリックし、下記2ファイルをダウンロードしてください。
・car.data:ローデータ。カンマ区切りになっているので、「car.csv」にリネーム。
・car.nemes:フィールド名。中身はテキストファイルなので、エディタで開ける。
2.「Data Refinery」でデータ加工する。
データ加工から分析までシームレスに行えるのが、Watson Studioのメリットの一つです。Excelでも可能なデータボリュームですが、Watson Studioの「Data Refinery」でデータ加工を行います。
Watson Studio上でのプロジェクト作成や「Data Refinery」へのデータ取り込みは、下記エントリーをご覧ください。
Watson Studioの「Data Refinery」機能で「馬の疝痛(せんつう)」データを眺めてみた。
3.「Data Refinery」でフィールド名を変更する
このツール的には、「カラム」と言った方がいいかもしれませんが、ややこしいので「フィールド名」とします(馴染みにくければ「レコード名」で)
「car.csv(data)」を取り込んだ直後は、フィールド名がないので、「car.names」に記載されている名称でリネームしてください。
下記画像にあるように、フィールド名の横の鉛筆マークを押すと、リネームできます。
ちなみにフィールド定義は、下記の通りです。
-青文字が説明変数に当たるフィールド、緑文字が目的変数に当たるフィールドです。
-フィールド名の最初にある数字は、左からのフィールド順番です。
「クルマの受容性」に関する回答が入っています。
CAR car acceptability
. PRICE overall price
. . 1.buying buying price
. . 2.maint price of the maintenance
. TECH technical characteristics
. . COMFORT comfort
. . . 3.doors number of doors
. . . 4.persons capacity in terms of persons to carry
. . . 5.lug_boot the size of luggage boot
. . 6.safety estimated safety of the car
. 7.Class

入力が完了しましたら、画面右上(右向き矢印の左横)のボタンを押し、データ加工手順を保存してくだい。その後、右向き矢印を押すことで、データ加工が実行され、フィールド名が変更されたローデータが生成されます。
「Watson Studio Modeler flow」の手順
1.「Modeler flow」をプロジェクトに追加する。
先ほど、「Data Refinery」でローデータを追加したプロジェクトに戻り(※)、「Add to project」から「Modeler flow」を選択してください。
※画面左上の「My projects/ Car_Evaluation」の買いそうです

少し待つと「Modeler flow」が立ち上がります。

2.「Import」から「Data Asset」をドラッグ&ドロップ。
左側にある「Import」メニューから「Data Asset」を、右側のキャンバスにドラッグ&ドロップしてください。

3.「Data Asset」をOpenし、分析データを読み込ませる。
配置した「Data Asset」の上にカーソルを当てると、右上に「・」が縦に並んだマークが表示されます。これを選択し、「Open」を選んでください。

「Change data asset」を選択してください。

「Data assets」から読み込ませたいデータを選択してください。私の場合、「Data Refinery」でフィールド名を加工したデータを選んでいます。

4.データチェックする。
念の為、データ内容のチェックをしましょう。この辺り、通常の「SPSS Modeler」とやることが同じですね。左側の「Outputs」メニューから「Table」ノードを配置してください。
結線は、配置した「Data Assets」を選択すると、当該ノードの右側に小さな丸が表示されるので、それをドラッグ&ドロップして、「Table」ノードの丸に繋げるだけです。

「Table」ノードを選択し、メニューから「Run」を実行してください。
数秒後、右側の「Outputs」タブにTableが表示されるのでクリックしてください。
なお、「Outputs」タブの右上にあるアイコンは、過去に出力されたアウトプットを表示/非表示するためのアイコンなので、覚えておくと便利です。
また、各アウトプット名をクリックして表示されるメニューから、各アウトプットをRemove(削除)可能です。

テーブル情報が表示されます。フィールド名が「Data Refinery」で加工した名称になっていますね。
元の「Modeler flow」画面に戻りたい場合は、画面上段のメニューから1階層上のパスを選んでください。

続いて、「Outputs」メニューから「Data Audit」を選び、「Data Assets」から結線してください。
「Table」と同様、「Run」してください。

すると、各フィールドのGraphやMeasurementなどを表示する画面が立ち上がります。
下段にスクロールすると、欠損値情報なども一覧できるため、とても便利です。
なお、通常の「SPSS Modeler」だと、グラフをクリックすると拡大表示可能ですが、「Modeler flow」ではサムネイル表示のみとなります。


5.「Partition」ノードを配置する。
「Field Operations」メニューから「Partition」ノードを配置してください。
当該ノードメニューから「Open」を選んでください。

「Training Partition」を「80」、「Testing Partition」を「20」にしてください。
両方とも手入力でインプット可能です。入力が完了しましたら、右下の「Save」ボタンを押してください。

6.「Type」ノードを配置する。
「Field Operations」ノードから「Type」ノードを配置した上で、「Partition」ノードから結線してください。この後、当該ノードの「Open」を選んでください。

「決定木(Decision Tree)」を実施するために、目的変数(Target)の選択が必要です。
今回は、「クルマへの受容性(「受け入れられるか」の度合い)」を知りたいので、「Data Refinery」でリネームした7番目のフィールド(私の場合は「class」と命名)を「Input」から「Target」に変更し、「Save」ボタンを押します。

7.「C5.0」ノードを配置する。
「Modeling」メニューから「C5.0」ノードを選択し、「Type」フィールドから結線します。当該ノードの「Run」を選択してください。

8.決定木モデルのナゲットを選択する。
Modelerのflowが回り始めて数秒後、「C5.0」ノードから自動的に決定木のナゲットが結線されるので、ナゲットのメニューから「View model」を選んでください。

「Model Information」画面です。生成したモデルの基本情報が表示されます。

「Feature Importance」画面です。各説明変数の重要度が一覧化されます。
この場合、「安全性」→「シート数」のようです。

決定木ルールが上位から一覧化されます。
目的変数が「クルマへの受容度」なので、「安全性の低いクルマは無いわ〜」な感じですね。

「Tree Diagram」画面です。先ほどの「Decision Rules」がビジュアライズされます。
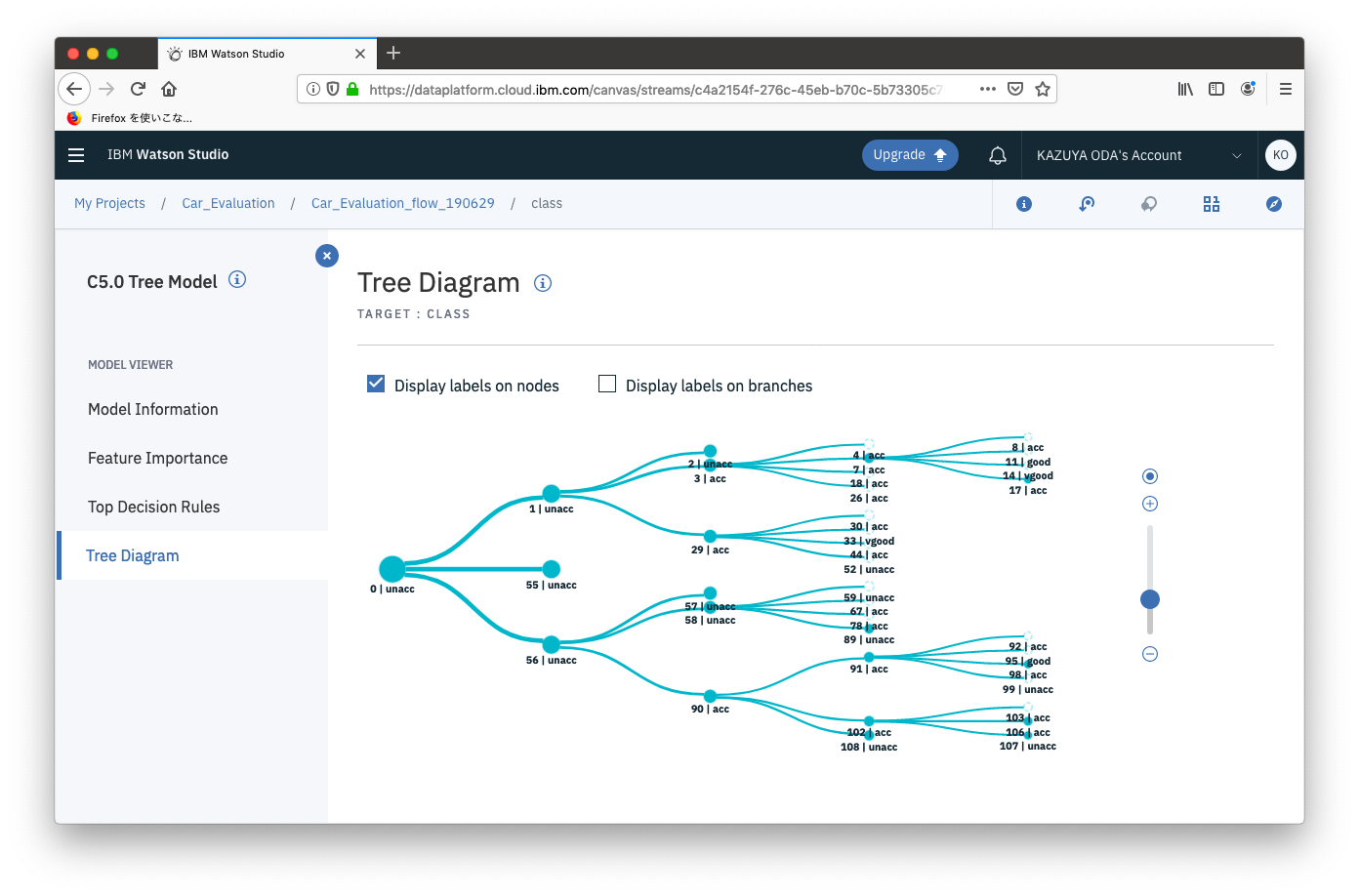
右上の「Display labels on branches」を押すと、ラベルが表示されます。

最後にオマケです。
flow画面に戻って、右上の「↓」ボタンを押してください。

下記のようなダイアログが表示されるので、ローカル端末上にある「SPSS Modeler」で開いてください。
お持ちでない方は、無料体験版を別途ダウンロードして設定してください。

難なく開きましたっ!
これ、結構すごいですよね。ご利用経験のある方はご存知かと思いますが、「SPSS Modeler」は超高性能なデータマイニングツールではありますが、その分、結構なお値段になります。
それが「Watson Studio」の無料機能でこんなにサクッとModeler flowが作れてしまうのは驚きです。
もちろん、ローカル版のModelerと比べると出来ないことや、やや手順が増えるユースケースもありますが、「Watson Studio」上にある「Rstudio」や「Jupyter notebook」などを併用すれば、結構近しいことが実現できそうです。
今後も、色々と「Watson Studio」の各機能をご紹介できればと思っています。
<補足>
「Analysis」ノードも入れときました。「Outputs」メニューから「Analysis」ノードを追加し、決定木のナゲットから結線してください。
当該ノードをOpenし、「Performance evaluation」にチェックを入れて「Save」し、「Run」してください。

精度評価結果が表示されます。

ご参考:その他のWatson関連エントリー
(Watson)Personality InsightsのJSONをR言語でパースしてみた
Watson Studioの「Data Refinery」機能で「馬の疝痛(せんつう)」データを眺めてみた。
https://sapporomkt.blogspot.com/2019/06/watson-studiodata-refinery.html
Watson AnalyticsとMeCabで「老人と海」を軽く可視化してみた。
https://sapporomkt.blogspot.com/2017/08/watson-analyticsmecab.html
Watson Explorerでディズニーの人気作品をテキストマイニング
http://sapporomkt.blogspot.jp/2017/04/watson-explorer.html
いま話題のIBM「Bluemix(ワトソンくん)」が「老人と海」をサマったら。
http://sapporomkt.blogspot.jp/2015/11/ibmbluemix.html
https://sapporomkt.blogspot.com/2019/06/watson-studiodata-refinery.html
Watson AnalyticsとMeCabで「老人と海」を軽く可視化してみた。
https://sapporomkt.blogspot.com/2017/08/watson-analyticsmecab.html
Watson Explorerでディズニーの人気作品をテキストマイニング
http://sapporomkt.blogspot.jp/2017/04/watson-explorer.html
いま話題のIBM「Bluemix(ワトソンくん)」が「老人と海」をサマったら。
http://sapporomkt.blogspot.jp/2015/11/ibmbluemix.html














