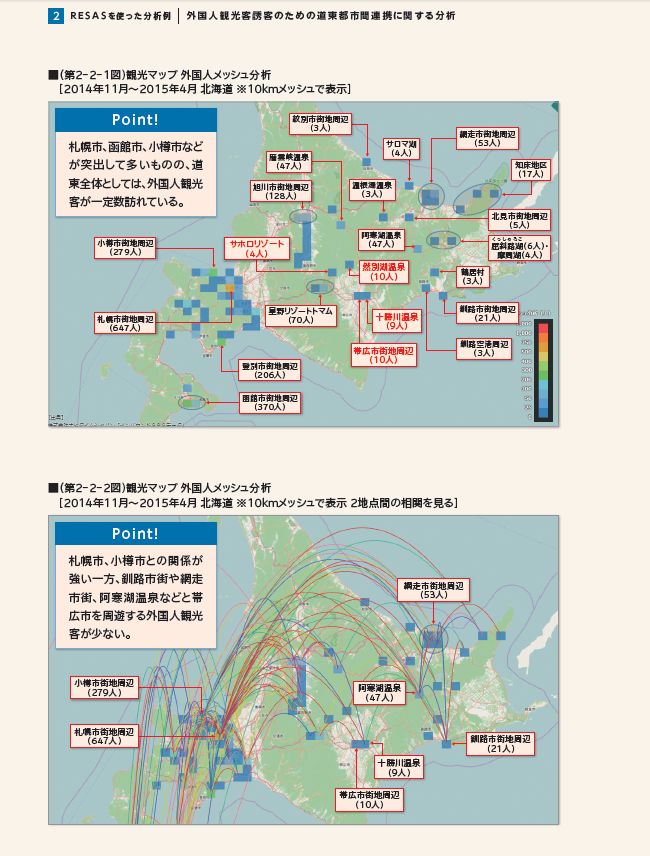
前回は、日本におけるサラブレッドのサイアーランキングデータを使ってレコード追加等をお勉強しました。
SPSS Modelerでリーディングサイアーデータ分析:前処理(レコード追加等)
http://sapporomkt.blogspot.jp/2016/05/spss-modeler.html
競馬ファンとしては、日本のサラブレッド競争馬の父であるリーディングサイアーを見たからには、「母の父」にあたる「ブルーメアサイアー」との関係性も見たくなるもんです。 毎度のことですが、異論は認めません(笑)
例えばこんなイメージで
※本エントリーは、私、小田一弥が一個人として勉強を兼ねて記載したものです。
私の勤務先である日本アイ・ビー・エム株式会社の見解・見識ではない、個人としての記載内容としてご覧ください。
もう少し、「ブルードメアサイアー」のウンチクを。
Wiki曰く、下記でございます。
「ブルードメア」は「繁殖牝馬」を意味し、「サイアー」は「(特定の馬に対する)種牡馬」「父馬」を意味する。母の父。頭文字をとってBMSと略されることも多い。
競走馬生産者の間では、父馬、母馬、ブルードメアサイアーが競走馬の能力に強く影響を及ぼすと言われ、ブルードメアサイアーとしての勝利回数、入着賞金額を集計したランキングも存在する。
そんなに難しくなかった「レコード結合」の手順
私、SPSS Modelerは初心者なので「レコード結合」ノードは始めて触ったのですが、思っていたよりも簡単でした。
1.「Excel」ノードでブルードメアサイアーデータを読み込み
前回エントリー同様、日本における2007~2016年におけるブルードメアサイアーデータを準備し、「Excel」ノードで入力しました。ちなみに、今回は各年度で全データを集めるのは大変だったので、上位300頭だけにしたため、若干数値がずれると思いますがご了承ください。
すべて入力後、 「レコード設定」パレットの「レコード追加」ノードでデータをつなげてください。
「リーディングサイアー」同様、ストリームが見づらくなるので、「スーパーノード」で格納すると便利だと思います。
2.「テーブル」ノードで確認
このあたり、もう慣れましたよね。一応、読み込ませた内容をチェックしてください。
ここでは「種牡馬名」をキーにして「リーディングサイアー」データと結合させるのが狙いです。
3.「レコード集計」ノードで各指標を集計
こちらも前回エントリーと全く同じ手順です。
4.「レコード結合」ノードで「リーディング/ブルードメアサイアー」を結合
「レコード設定」パレットから「レコード結合」ノードを選択し、下記のように結合させてください。
(「フィルター」ノードは途中でフィールド名を変えただけなので無視してください)
「レコード結合」ノードを開くと、下記のようにどのノードから接続されたかわかるようになっているので、注釈で命名しておくといいですね。
「レコード結合」タブで「種牡馬名」を結合キーに指定します。
5.「フィールド順序」ノードでフィールドを並び替え
いつもどおり、ご自分で見たいフィールドの順番に並び替えてください。
6.「ソート」ノードで降順/昇順を指定
こちらも同様に、各フィールドにおけるレコードの表示順を指定してください。
7.「サンプリング」ノードでレコードを抽出
今回、初めてご紹介するのが「サンプリング」ノード。「レコード設定」パレットにあります。
下記のように設定すると先ほどのソート順に上位20レコードを抽出してくれます。
8.「散布図」ノードを配置
あとは「散布図」ノードを使って、下記のように設定します。
X軸:リーディングサイアーの収得賞金全額(07~16年)
Y軸:ブルードメアサイアーの収得賞金全額(07~16年)
散布図におけるプロット名:種牡馬名
下記は冒頭に掲載した散布図です。実はやる前からわかっていたのですが、今回のやり方だけでは両者の関係性をしっかり見ることは出来ません。それは、「ブルードメアサイアー」は「母の父」なので、「父」よりも1世代ずれてしまうからです(種付け+出産+デビュー期間までの育成期間)
もし精緻に関連性を見るのであれば、「初年度デビュー産駒に限定する」といったデータの取り方が必要になると思いますが、今回の目的は「種牡馬名をキーにしてレコードをつなげる」ことなのでご容赦ください。
とはいえ、散布図を俯瞰すると、ブルードメアで「サンデーサイレンス」が突出していることがわかりますね。「ディープインパクト」の父としても有名な大種牡馬ですが、死没したのは2002年なので、リーディングサイアーでもそこそこのポジションにいることは、実は凄いことですね。
こちらは各年度における「AEI」の合計値をX軸:リーディングサイアー、Y軸:ブルードメアサイアーでプロットしたものです。「AEI」は1頭における獲得賞金の大きさを示す指標なのですが、Y軸を見ると「メジロマックイーン」が突出して高いことがわかります。
当馬は日本のクラシックレース三冠を達成した「オルフェーヴル」やクラシック二冠や有馬記念を制した「ゴールドシップ」の母の父としても有名ですね。「サンデーサイレンス」のようにケース(頭数)が多くなくても、前述した大物を算出すると下記のような結果になりやすいということですね。
今回は、完全に趣味の世界に走ってしまったので、次回はもう少し分析チックなことをやってみる・・・かもしれません(笑)
その他:SPSS Moder関連エントリー
SPSS Modelerでアソシエーション分析がしたいっ! (前処理編〜縦持ちを横持ちへ)
http://sapporomkt.blogspot.jp/2017/06/spss-modeler.html
「SPSS Modeler」におけるデータ操作及びシーケンスデータの取り扱いまとめ
http://sapporomkt.blogspot.jp/1970/01/spss-modeler_1.html
SPSS Modelerでリーディングサイアーデータ分析:前処理(レコード追加等)
http://sapporomkt.blogspot.jp/2016/05/spss-modeler.html