知人や友人に「Rっていいよ!」と熱っぽく進めるものの、不慣れな方だと開発環境を準備するだけでも大変なのは事実と言えば事実。
Rの開発環境といえば「RStudio」が有名ですが、R(r-base)のバージョンと合わせる必要があったり、個別パッケージにもバージョン問題があったりと・・・まぁ、オープンソースなのでそれなりに手間がかかるとです。
しかーし!そんなあなたに朗報です!
出でよ、ロデーム!(古いw)・・・じゃなくって、「Data Scientist Workbench」!!
今日は、このサービスを使って、下記のようなグラフを作ってみます。

※本エントリーは、私、小田一弥が一個人として勉強を兼ねて記載したものです。私の勤務先である日本アイ・ビー・エム株式会社の見解・見識ではない、個人としての記載内容としてご覧ください。
「Data Scientist Workbench」とは
IBMが提供する無料のデータサイエンス作業環境です。簡単な利用登録だけで、下記のデータ準備/分析環境が即座に利用可能になります。
<データ準備環境>
・OpenRefine
<データ分析環境>
・Jupyter Notebook
・Zeppelin Notebook
・RStudio IDE
・Seahorse
利用申請は下記サイトの解説を御参照ください。
Data Scientist Workbench 入門
手順とサンプルコードのご紹介
1.利用申請後、「Data Scientist Workbench」にアクセス。
https://my.datascientistworkbench.com/
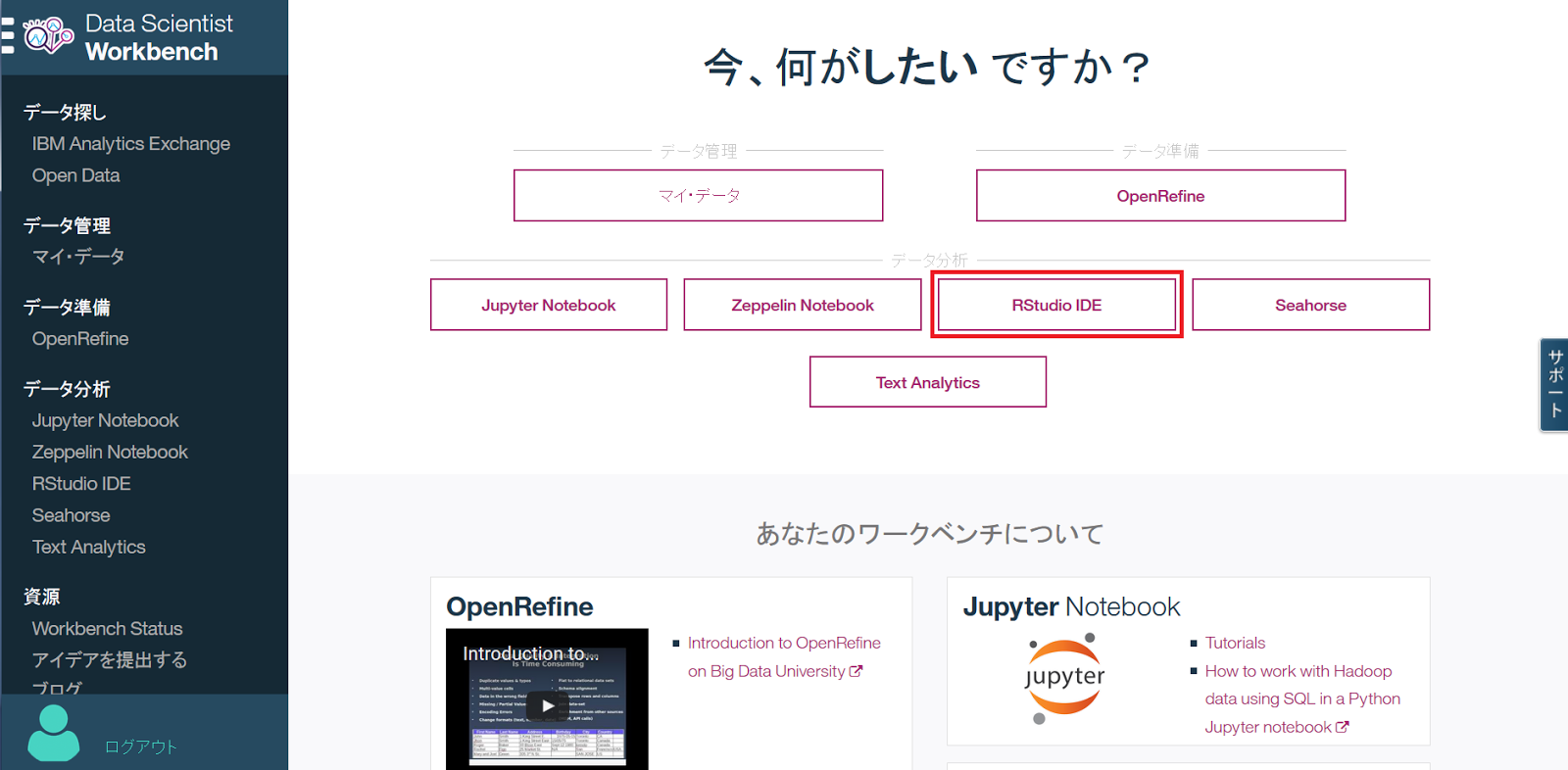
2.「RStudio IDE」をクリック
下記画面の赤枠内にある「RStudio IDE」ボタンをクリックしてください。
「今、何がしたいですか?」って、まぁ、直球ですね(笑)
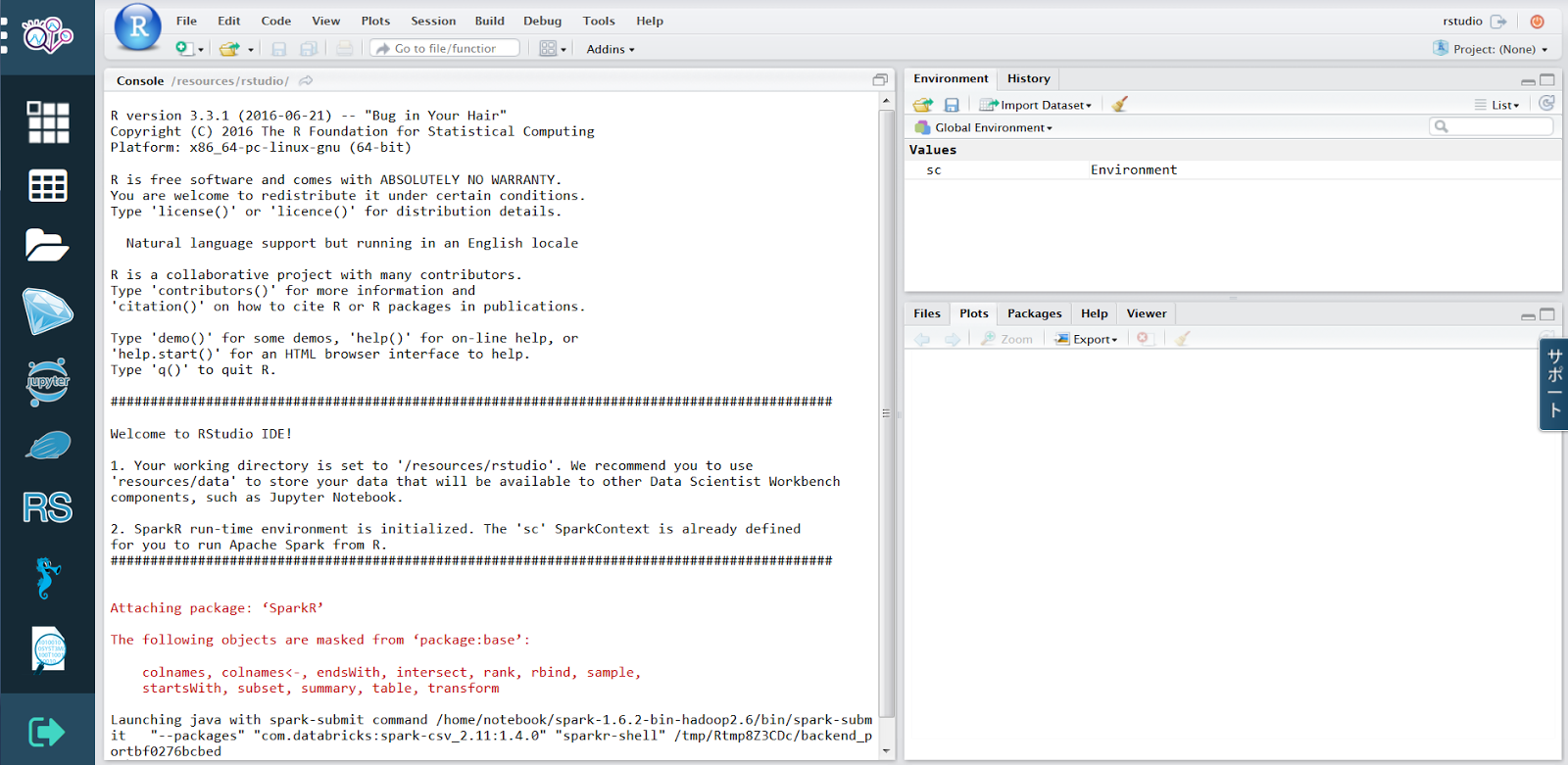
3.下記コードを実施
上記ボタンをクリックした後、「準備できるまで2~3分かかります」的なメッセージが表示されますが、実際はそんなにかかりません。
下記のようにローカルPCにインストールする「RStudio」と同じ画面が表示されるはずです。
# 必要なパッケージのインストール
install.packages("gridExtra")
install.packages("ggplot2")
# 必要なパッケージのロード
library(ggplot2)
library(gridExtra)
# Jared P.Landerさんが公開しているNYCのオープンデータを読み込ませます。
# ちなみにこの方、「みんなのR~データ分析と統計解析の新しい教科書」の著者さんですが、この本、とっても分かりやすくて、かつ実践的なのでオススメです。
housing <- read.table("http://www.jaredlander.com/data/housing.csv",sep=",",header=TRUE,stringsAsFactors = FALSE)
# Lander先生の御指示どおり、列名を変えます。
names(housing) <- c("Neighborhood","Class","Units","YearBuilt","SqFt","Income","IncomeperSqFT","Expence","ExpencePerSqFt","NetIncome","Value","ValueperSqFt","Boro")
# お部屋のUnit数が1000以上って「?」なので、Units1000未満に絞り込みます。
housing <- housing[housing$Units < 1000,]
# 下記のようにするとdataframe名を都度指定しなくても済みます。今回は不要ですけど。
# ちなみにattachを外すときは、「detach()」でお願いします。
attach(housing)
# ggplto2で各グラフを生成します。ちなみに「fill = Boro」は「Boro別に表示してね」の意味です。
Units.graph <- ggplot(housing, aes(x = Units, fill = Boro)) + geom_histogram()
YearBuilt.graph <- ggplot(housing, aes(x = YearBuilt, fill = Boro)) + geom_histogram()
ValueperSqFt.graph <- ggplot(housing, aes(x = ValueperSqFt, fill = Boro)) + geom_histogram()
Income.graph <- ggplot(housing, aes(x = Income, fill = Boro)) + geom_histogram(binwidth = 500000)
# 4つのグラフを2列に配置
grid.arrange(Units.graph,YearBuilt.graph,ValueperSqFt.graph,Income.graph,ncol = 2)
# 冒頭のグラフが表示されます。ggplot2なので、とても艶っぽくて「それっぽい」感じです。

0 件のコメント:
コメントを投稿